
3 Tips to Succeed as a Data Scientist
I wanted to write this blog post because as I know all too well, it can be quite challenging to start a new job as a data scientist, particularly if you are coming from another profession as I did or if it is your first job. In this post, I wanted to discuss some of the main struggles I faced and also some general tips and advice to make life easier for those starting out in this role.


Daniel Foley
I wanted to write this blog post because as I know all too well, it can be quite challenging to start a new job as a data scientist, particularly if you are coming from another profession as I did or if it is your first job. In this post, I wanted to discuss some of the main struggles I faced and also some general tips and advice to make life easier for those starting out in this role. Obviously, this is based entirely on my own experience and others may have faced different challenges but I think these tips are general enough that at least some of them are applicable to those starting out in a data science role.
There are a few things in particular that I want to talk about that I think are really important. These are:
- Working with Stakeholders
- Analytical Workflows
- Continuous Learning and Development
Working with Stakeholders
The first of these points is maybe the most important and really feeds into the points that follow. Working with stakeholders is something I struggled with initially and I am sure other data scientists have faced this problem. It really stems from a knowledge mismatch between the data scientist and the stakeholder which goes both ways. Usually, the stakeholder does not have in-depth knowledge of coding, analytics or machine learning and the data scientist, particularly if they are new to the business lacks business or domain-specific knowledge. In short, they don’t speak the same language. So what kind of implications does this have?
At best it can lead to some confusing conversations and at worst it can lead to a serious amount of time being wasted working on the wrong problems. I would generally say that it is up to the data scientist to make sure they understand the stakeholder, in particular their goals and what they are trying to achieve. In my experience, questions or problems from stakeholders can often be quite vague and difficult to translate into an analytical question or model. The good news is that this gets easier over time.
Things that I learned
- Try to speak in their language. By this, I mean to try and frame your solutions to things they will understand. You can implement a fancy model that has 99 per cent accuracy but what does this actually mean in business terms? Try and link your analytic solutions to KPIs they care about or express the expected impact in revenue terms, everybody understands money. Here is an example of one way of doing this.
- Use simple visualisations. Violin Plots are not simple, even if they do look great and can tell you a lot about your data. (they can be particularly confusing for people if your data doesn’t follow a normal distribution, go for a box plot or even a bar chart and put the more complicated stuff in the appendix. Direct people to this if they want to see more detail.)
My Advice
- It is ok to say no if you think projects are unlikely to be successful: you can always think about how you can redefine the original goal into a related and achievable goal or move onto a new problem. If you are new to your role, ask your team members what they think. They will usually be able to advise you on what problems are doable. Of course, it may be the case that nobody has worked on this problem before and so there is a high level of uncertainty. In this case, I would suggest defining some initial exploratory goals and be willing to move on if results do not look promising. This can help avoid wasting too many resources on the wrong problems.
- Talk to your stakeholders regularly. It is your job to understand what your stakeholders want and to determine if it is feasible. You should regularly update your stakeholders on the progress of your work and the likely direction it may take. They will likely have some useful insights and suggestions for you to make sense of your results.
- Learn how to explain things in a non-technical way. This is so important when you are speaking to stakeholders. You need to think about your audience, are they technical or non-technical? This goes for any type of communication whether it is a presentation, a meeting or in an email. It is important to know this in advance if possible as it can help you set the level of your explanation. If you can’t convince people what are doing is valuable it likely won't be implemented. I still struggle to do this sometimes without using jargon but practice makes perfect I guess. Using good visualisations can often by more impactful than a written or spoken explanation.
- Try to develop a story around your analysis or results. This is heavily related to the point above but if you can develop a story around the problem it can be a very effective tool for your work to make a lasting impression. Try and consider the following questions. What is the problem you are trying to solve? why is it important? and what impact can your solution have om the business?
- Solutions are rarely perfect. Most of the time you cannot implement a perfect solution. You will usually have to make tradeoffs and the end solution will not be without its limitations. It can be quite tricky to decide what method is correct but in general, I would have a preference for the simplest solution (Occam’s Razor). For example, if you are modelling, stick to something simple like Logistic regression at least initially. In my experience, people are generally hesitant to use black box solutions. You can also make use of tools such as SHAP or LIME for improving model interpretability. Recently, I have been playing around with a library called explainerdashboard to try and make my models more transparent.
Analytical Workflows
In this section, I want to describe some general principles for analytical work and how we can design workflows that are reproducible and more efficient. The tools and workflow I use will differ slightly depending on the task but I will walk through an example of the type of problems I have worked on and some of the tools that I consider to be really useful.
This is a slight digression but the first tip for anyone wishing to make an impact as a data scientist is to get good at SQL. It doesn't really matter which flavour but becoming proficient in SQL is extremely important. The one thing in common with all of the projects that I have worked on in my current role is SQL. All of the data scientists on my team use SQL daily for their analytical work. We also try to upskill and encourage non-data scientists to use it and even quite simple queries can give powerful insights. The good news is that it is pretty easy to learn the basics of SQL. For more advanced queries, we generally just build upon the ideas of the basics. One course that I found really useful when I was upskilling my SQL was this course on Udacity. It covers the basics and also gets into more advanced topics using a realistic case study. I highly recommend it to anyone wanting to improve their SQL skills. I would also recommend going through some of these problems as they are likely closer in complexity to what you would find in the real world.
Another point I think is important to mention is to spend some time really trying to understand your companies data. If you are lucky enough to be in a company with good data engineers and data infrastructure then this step will be a lot easier. In general, answering some of the following questions will make constructing queries much easier and leave less scope for errors. (Many of these can be answered if you have a good ERD of your data warehouse).
- What are the key tables you are likely to use?
- How are the tables structured? i.e. what are the data types of columns?
- How do tables relate to each other? i.e. one to one, one to many relationships (important for joins: I have been stung by this before)
- How are missing values recorded? i.e. if a user didn't make a payment today is that recorded as null or 0? (this can impact aggregates like averages)
- How and when are the tables updated?
Ok, so we have talked a little bit about the importance of SQL. Before we jump into analysis and start coding in SQL or Python it is a very good idea to write out a high-level plan of what we need to do. This is a must when beginning a project as it can keep you from getting sidetracked from the main goals of the project. For this I generally use Trello. When starting a new project I create a board and usually have a background list, a to-do list, a doing list and a completed list. I will then create a few cards which give an overview of the problem, the objectives and the deliverables. It is often a good idea to have your stakeholders added to this board as well and this can provide the basis for discussion points at meetings. Now you could also do this using another tool but the takeaway is that we have clearly laid out some key information about the project.
Let’s take an example of a project and talk about the workflow and some of the tools I use. Assuming I have a project where I need to do some exploratory modelling, what would this workflow look like?
Assuming I have already created a high-level plan in Trello. The next thing I would do when starting my analysis is to create a git repo. I'm sure I don’t need to explain the importance of version control to any of you but this is a vital component for analytical projects. In the same vein, I usually create a new Conda environment with the set of libraries I most frequently use. You can always go a step further and use a docker container. To maintain a consistent project structure we could also use cookiecutter to create a template of a typical data science project. Creating a standardised project template like this can be very helpful for yourself and others on your team especially if they will be reviewing your work. I do most of my coding work, particularly exploratory analysis in Jupyter notebooks or Jupyter lab. You can also add different Conda environments to Jupyter notebooks which make switching between multiple environments very simple. The code below shows how to create a new Conda environment, add it to Jupyterlab and set up the cookiecutter data science template. If you have Jupyterlab installed in your base environment then you can launch Jupyterlab and switch between conda environments easily.
conda create --name ds_env python=3.7
conda activate ds_envconda install -c conda-forge cookiecutter
cookiecutter https://github.com/drivendata/cookiecutter-data-scienceconda install -c anaconda ipykernel
python -m ipykernal install --user --name=ds_env
If I am working with a lot of data or need more compute, rather than working locally I tend to use AWS Sagemaker. This is particularly useful if the model you are working on will be put into production on AWS. It is also very easy to share notebooks with colleagues. There are a bunch of nice features on AWS for machine learning such as a variety of built-in models, automatic hyperparameter tuning and integration with git but I won't dive into these in this post but if you are interested AWS have a great blog which describes some of these features in detail.
If the project I am working on is more ETL related or involves changing production code I tend to use VScode. I am a big fan of this IDE and there are many extensions that you can add on that can make your life easier. After adding the python extension we get some really useful functionality such as a debugger (very useful), syntax highlighting, autocomplete and IntelliSense. You can also use Jupyter notebooks directly from the IDE which is an added bonus.
One other tool that I recently started using is MLflow. It is a tool for managing the machine learning lifecycle. In general, it makes it much easier to track your model experiments, improves reproducibility and makes deployment easier.
The final tool that I regularly use is Confluence. You can use whatever you want here really as long as you are documenting your work. This is not only important for ourselves but also to show the approach and results of our work to team members and other colleagues. Having this central repository of work that the team has done is incredibly useful and makes it very easy to share insights and results from the different projects teams are working on. One more thing I would suggest is to heavily document your code whether it is SQL, R, Python, whatever. I can’t tell you how many times I have looked back at a query or a code snippet and wondered what the hell I was trying to do. Write comments, particularly for complicated logic. You will thank yourself later, I promise.
Summary of the Main Tools I use
- Trello
- Git
- Cookiecutter
- Conda environment / Docker.
- Jupyter Lab / Sagemaker / VSCode
- Confluence
Continuous Learning and Development
The final topic I want to discuss is that a data scientist needs to be continually learning. Having a hunger and willingness to gain knowledge is incredibly important as a data scientist. Data Science is such a nascent and vast field that it is almost impossible to know everything but gradually gaining more and more knowledge over time will be invaluable for your career. I have seen a number of articles recommending data scientists to specialise in a particular area to ensure they are an attractive prospect to employers. While I do not necessarily disagree with this I do think it is probably more important to get experience in a few different areas first, particularly within your company before heavily specialising in one area. One of the things I would recommend doing in order to develop your skillset is to make a development plan.
An outline of the areas or tools that you want to learn or improve on can be a great way to help you increase your skills. I suggest making a high-level development plan for yourself listing the goals you want to achieve over the next 6 months to one year. In my company, we are encouraged to make a development plan but this is something you can do on your own. However, it can be a good idea to share this with your manager as they may be able to provide training and projects for you to help you achieve these goals. This can also be a great exercise if you want to get into data science and will help you identify the areas you need to work on.
For example, for me personally, over the next year, I want to improve my knowledge of Cloud Infrastructure, in particular AWS. I would like to work towards getting the AWS Machine learning Speciality Certificate. I also want to improve my knowledge of deep learning. I am a big fan of online courses and am planning to take the Deep Learning specialisation on Coursera. Usually, after doing courses I like to try and create a personal project to reinforce the topics I have learned. Getting stuck into a project is a great way to test your understanding and will help you retain the information for longer.
For example, for these 2 goals above my high-level development plan looks something like the figure below. I create my high-level goals, list out how I plan to achieve them, what my key timelines are and also any resources that I think will help me along the way.
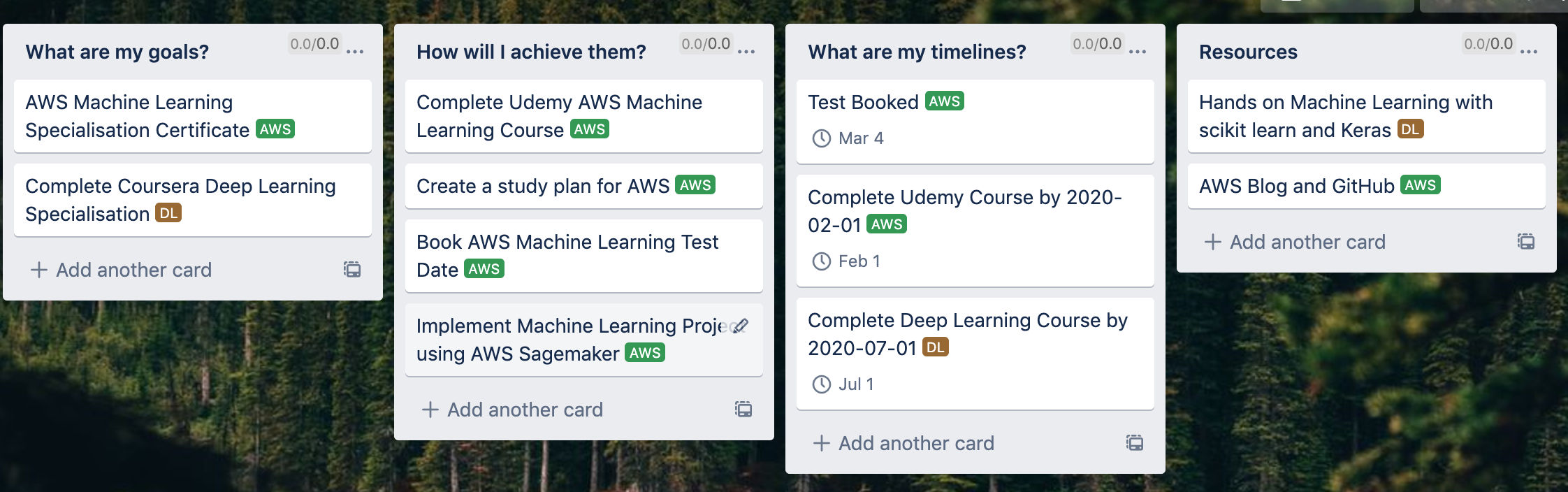
As well as a development plan, there are a few things I generally do when I am trying to learn something new. Hopefully, you will also find some of these tips useful.
One of the things people tend to struggle with the most, me included is actually getting started. i.e. sitting down and studying or working on problems. These things are difficult, in general, our brains are lazy, they don't like doing things that require effort. In order to combat this, I often try and give myself some sort of reward for doing work. It might be as simple as having a coffee after 1 hour of work or watching a youtube video. It sounds silly but it often just makes it that little bit easier to start.
This may seem obvious but find projects related to what you are learning and also your personal interests. For example, if you are learning about Random Forests and you enjoy basketball, use Random Forests to predict basketball game outcomes. This gives you a much better chance of sticking with it as you will enjoy it more. You may also have some pretty good insights into the data as you have some domain knowledge already.
My favourite way to learn has always been a combination of online courses, books and personal projects. Here is a list of resources that I have used in the past that I have found particularly useful to learn topics related to Machine Learning, Data Science and Programming.
Books
- Hands-on-Machine-Learning-with-Scikit-Learn-Keras-and-TensorFlow By Aurelien Geron: This book is recommended everywhere and for good reason. It contains a perfect combination of theory and code to get you estimating algorithms in python. I haven’t gone through the deep learning section yet but looking forward to reading it.
- Pattern Recognition and Machine Learning By Christopher Bishop: This book is not exactly an easy read but it contains really in-depth derivations and explanations of the main machine learning algorithms that you will come across. This book helped when I was learning about k-means and Gaussian Mixture Modelling.
- Data Science for Business: This is a good book for developing business intuition for data science. It also discusses the expected value framework in the context of machine learning which I found very useful.
- Practical Statistics for Data Scientists By Peter Bruce: Really useful as a revision of the main statistical concepts in data science. I used this to revise for Data Science interviews.
- Fundamental Methods of Mathematical Economics: Although this book has an economics spin, it contains pretty much all of the Maths you will come across in Data Science, bar the really advanced stuff. If you want to brush up on your Linear Algebra, Calculus and Optimisation I can't recommend this book more. It helped me get through my masters.
Online Courses
- Datacamp: I have taken a number of courses here and I particularly like the combination of videos and coding exercises. They also have some pretty interesting projects that you can try out.
- Bayesian Methods for Machine Learning: Great course on different applications of Bayesian Machine Learning. It is a good accompaniment to Pattern Recognition and Machine Learning above as they cover some of the same topics.
- Mathematics for Machine Learning Specialization: If your Maths is a little bit rusty I would check out this course. They cover some of the main topics you need to know before you start jumping into machine learning algorithms.
- Udacity: SQL for Data Analysis: A great course on SQL covering intro to more advanced stuff.
Note: Some of the links in this post are affiliate links.
Ok, that’s it for my tips and advice for succeeding as a data scientist. Hopefully, you found this useful and they can help you grow your skills as a data scientist. Feel free to check out my personal website below or connect on Linkedin.
Original Post: https://towardsdatascience.com/3-tips-to-succeed-as-a-data-scientist-3f2c3c48555f
Upvote
Daniel Foley
Data Scientist in the Mobile Game Industry

Related Articles